
Im Oktober 2022 stand ich vor dem IT-Lenkungskreis Digitalisierung unseres Mutterkonzerns. Auf der Agenda: Ein Vorschlag, der unsere gesamte Datenhaltung grundlegend verändern sollte – und der ein 6-stelliges Investment erforderte. Keine leichte Übung, wenn man bedenkt, dass im Raum Geschäftsführer, IT-Leiter und Entscheider saßen, die vor allem eine Frage hatten: Warum können wir nicht einfach weitermachen wie bisher?
Dass die Initiative am Ende nicht nur genehmigt, sondern vom Aufsichtsrat freigegeben wurde, lag nicht an der Technologie selbst. Es lag daran, wie wir die Entscheidung aufgebaut haben.
Die Ausgangslage ehrlich benennen
Bevor ich überhaupt über Lösungen sprach, musste ich das Problem greifbar machen – und zwar in einer Sprache, die nicht nur Entwickler verstehen. Unsere Datenhaltung hatte über Jahre hinweg Strukturen entwickelt, die historisch nachvollziehbar, aber nicht mehr tragfähig waren:
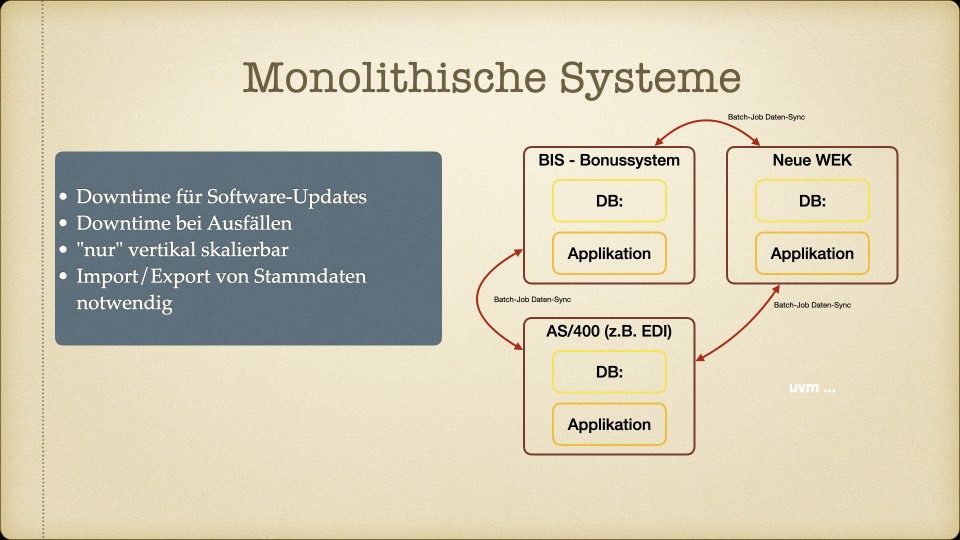
- Kein Single Point of Truth. Dieselben Daten lagen in verschiedenen Systemen, teilweise mit unterschiedlichen Ständen. Wer die “richtige” Version suchte, brauchte Erfahrung und Glück.
- Redundante Datenhaltung. Stammdaten wurden per Import/Export zwischen Systemen kopiert – ein fehleranfälliger Prozess, der regelmäßig zu Inkonsistenzen führte.
- Schnittstellen im Blindflug. Kein durchgängiges Monitoring, unvollständige Dokumentation, unklare Datenzugriffe. Wenn etwas schiefging, war die Fehlersuche Detektivarbeit.
- Nur vertikal skalierbar. Mehr Last bedeutete: größere Server kaufen. Irgendwann stößt man an physische Grenzen – und an finanzielle.
- Downtime als Normalzustand. Jedes Software-Update erforderte eine Wartungsphase. Jeder Ausfall betraf das gesamte System.
Das war keine Auflistung technischer Schulden für ein Entwickler-Meeting. Das war eine Risikobewertung für Entscheider.
Von Problemen zu Architekturzielen
Der entscheidende Schritt war, aus den Problemen keine Wunschliste zu machen, sondern klare, überprüfbare Architekturziele zu formulieren. Nicht “wir hätten gerne eine neue Datenbank”, sondern:
- Eine zentrale Datenhaltung in einer verteilten Datenbank – als Single Source of Truth für alle Systeme. Die Datenbank muss alle Daten vorhalten (auch historische), Teilausfälle ohne Datenverlust überstehen und mit Volumen und Last skalieren können.
- Ein einheitliches Datenmodell für die gesamte Eurobaustoff – kein organisch gewachsenes Nebeneinander mehr, sondern eine bewusst gestaltete Struktur.
- Ein dediziertes Team aus Datenbankexperten, das dieses Datenmodell verantwortet und pflegt.
- Revisionssichere Archivierung – bewusst ausgeklammert aus dem Datenbankprojekt. Hierfür setzen wir auf eine speziell zertifizierte Lösung (ELO), die die regulatorischen Anforderungen an Unveränderlichkeit und Auditfähigkeit erfüllt. Nicht jedes Problem gehört in dieselbe Lösung.
- Ereignisgesteuerte Verarbeitung, wo fachlich sinnvoll – weg vom Batch-Denken, hin zu reaktiver Datenverarbeitung.
Jedes Ziel war direkt an ein konkretes Geschäftsproblem rückgebunden. Nicht “Eventual Consistency” als Buzzword, sondern “keine widersprüchlichen Rechnungsdaten mehr bei unseren Handelspartnern”.
Die Architektur: Vier Schichten, ein Gedanke
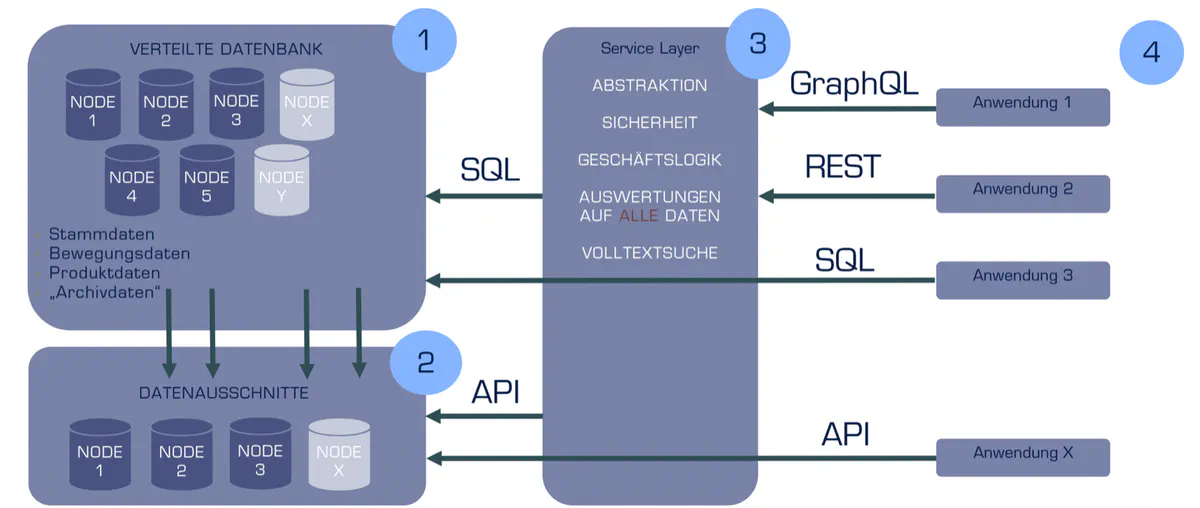
Statt die Lösung mit dem Datenbanknamen zu beginnen, habe ich eine Vier-Schichten-Architektur präsentiert, die zeigt, wie die Teile zusammenspielen:
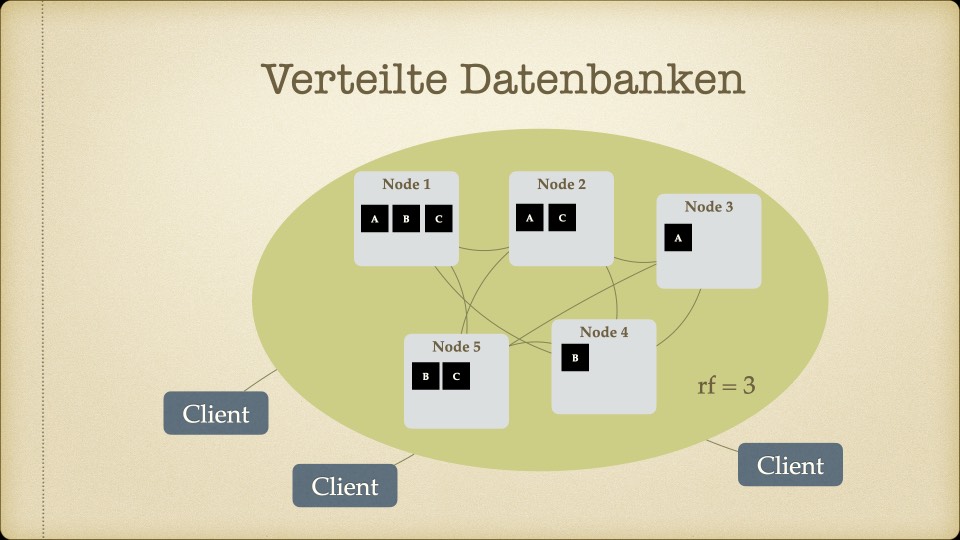
Schicht 1 – Verteilte Datenbank. Mehrere Nodes, horizontal skalierbar, jeder Node kann lesen und schreiben. Stammdaten, Bewegungsdaten, Produktdaten und Archivdaten an einem Ort. Mehr Kapazität? Neuen Node hinzufügen. Software-Update? Inkrementell, ohne Downtime. Das war der Punkt, an dem die Entscheider zum ersten Mal nickten.
Schicht 2 – Datenausschnitte. Nicht jede Anwendung braucht alle Daten. Dedizierte Cluster liefern gezielt Datenausschnitte für Elasticsearch, Suchfunktionen, Business-Auswertungen und Data-Mart-Szenarien – ohne die zentrale Datenbank zu belasten.
Schicht 3 – Service Layer. Die eigentliche Intelligenz: Abstraktion, Sicherheit, Geschäftslogik, Auswertungen über alle Daten, Volltextsuche. Kein direkter Datenbankzugriff mehr durch Anwendungen, sondern klar definierte, berechtigungsgesteuerte Services.
Schicht 4 – Anwendungen. Ob GraphQL, REST, SQL oder API – jede Anwendung greift über den Service Layer auf die Daten zu. Eine neue Anwendung anbinden? Eine API-Definition, keine Datenbankmigrationen.
Die Bereichsleiter abholen: Workshop “Verteilte Datenbanken”
Mit dem grünen Licht des Lenkungskreises für die grundsätzliche Richtung war der erste Meilenstein geschafft. Aber eine Freigabe für die Architekturvision ist noch keine Freigabe für ein konkretes Produkt mit einem konkreten Preisschild. Bevor wir CockroachDB als unsere Datenbank vorschlagen konnten, musste ich die Bereichsleiter und IT-Verantwortlichen mitnehmen – Menschen, die täglich operative Entscheidungen treffen und verstehen müssen, warum wir nicht einfach “eine größere Oracle-Instanz” kaufen.
Also habe ich einen internen Workshop vorbereitet: “Ein Ausflug in die Welt der verteilten Datenbanken”. Kein Sales-Pitch, sondern eine ehrliche Einordnung – von den Grundlagen relationaler Datenbanken bis zur konkreten Technologieauswahl.




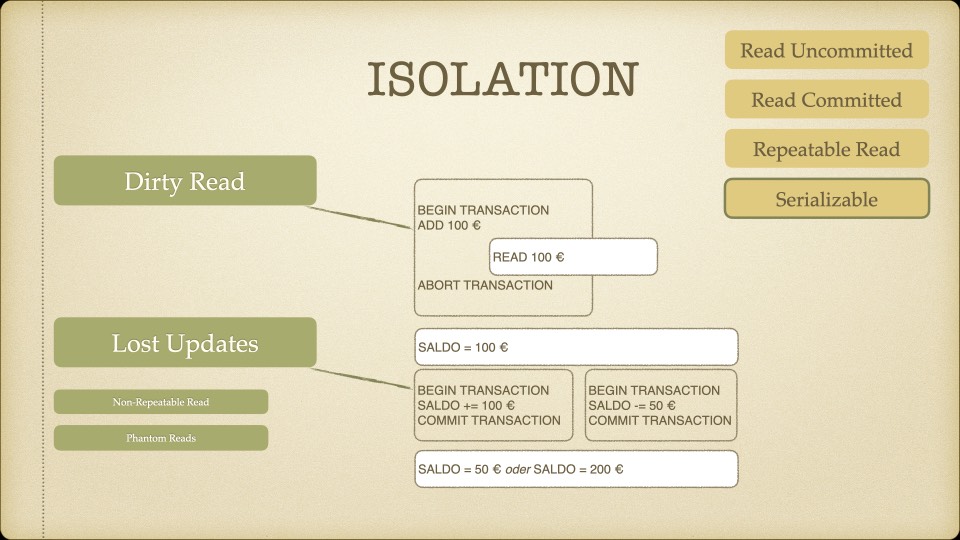













Vom CAP-Theorem zur Entscheidung
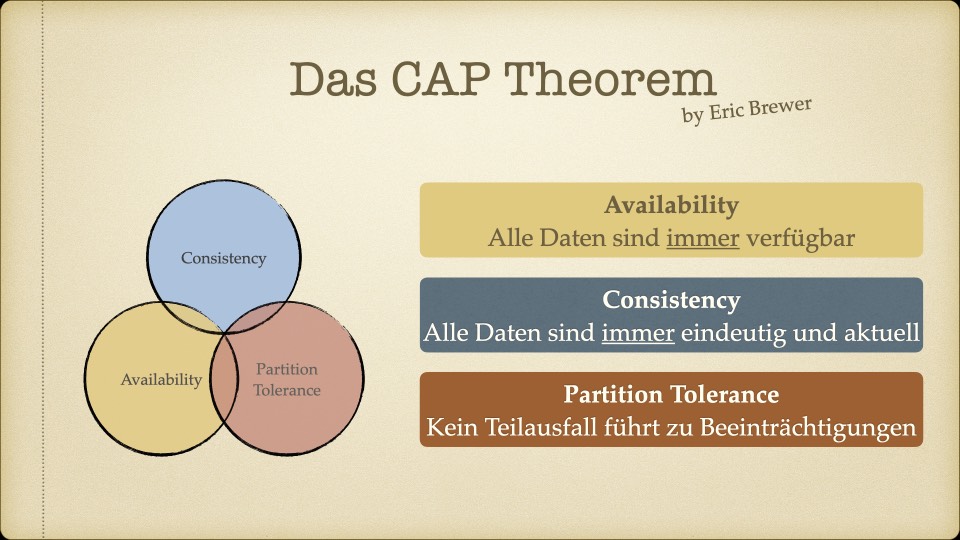
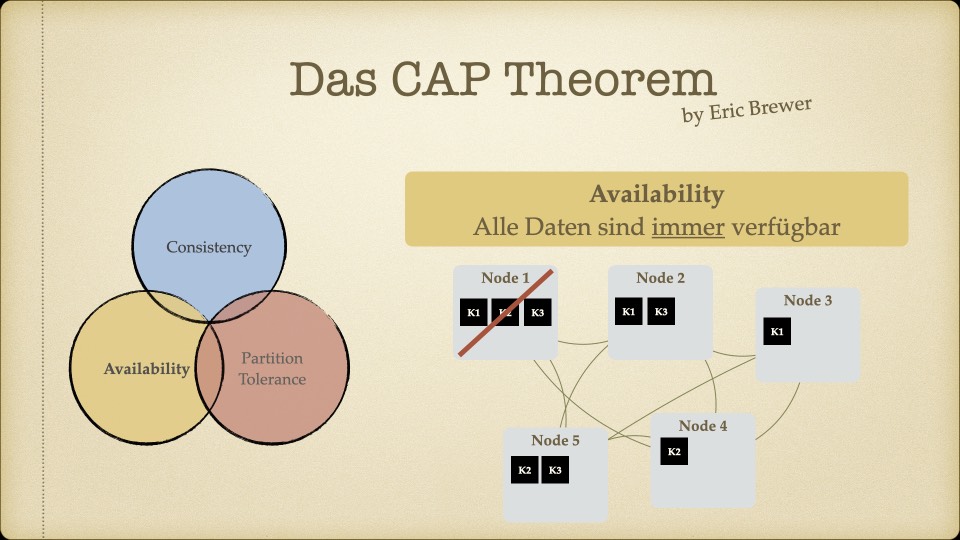
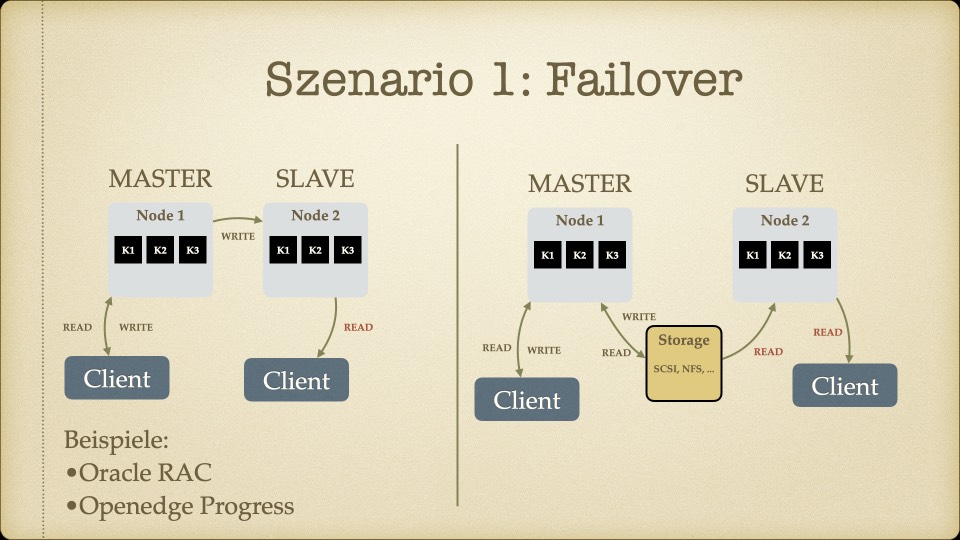
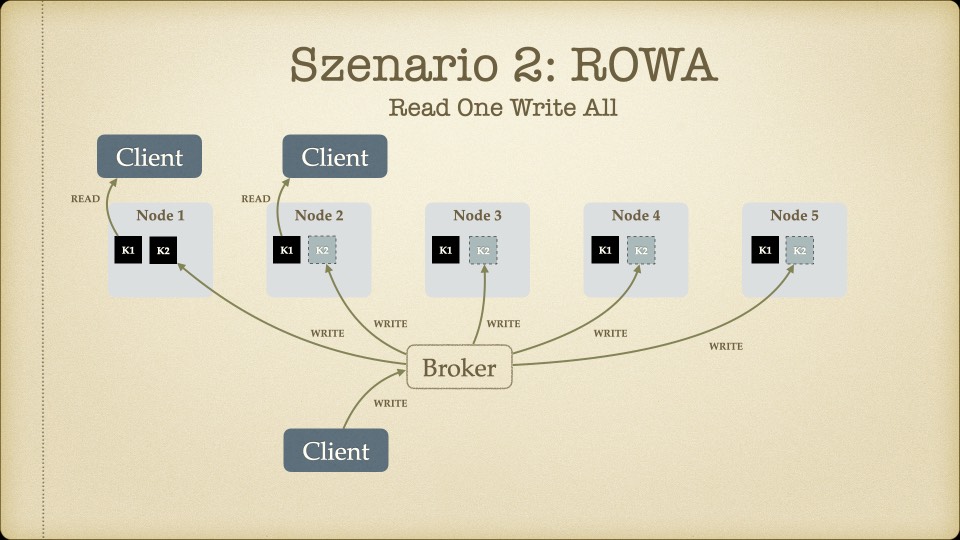
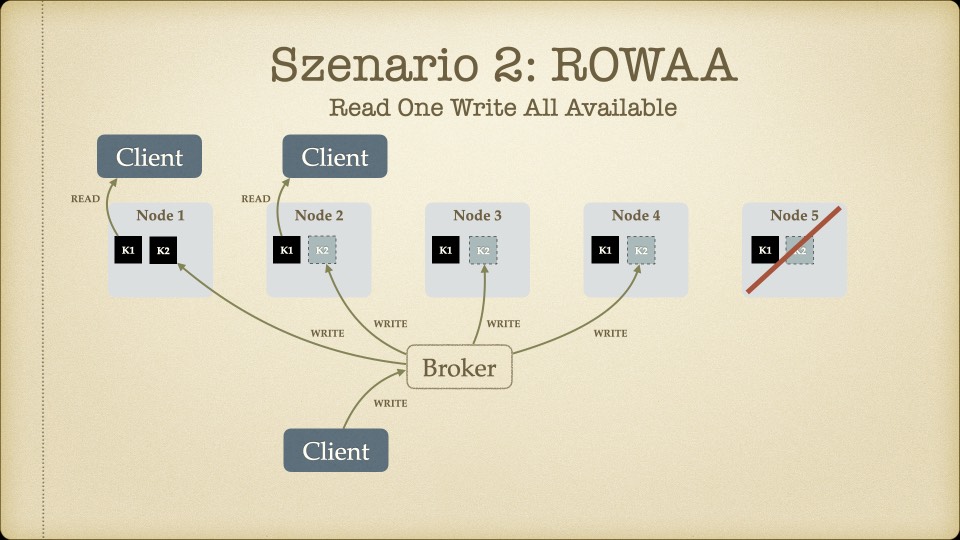
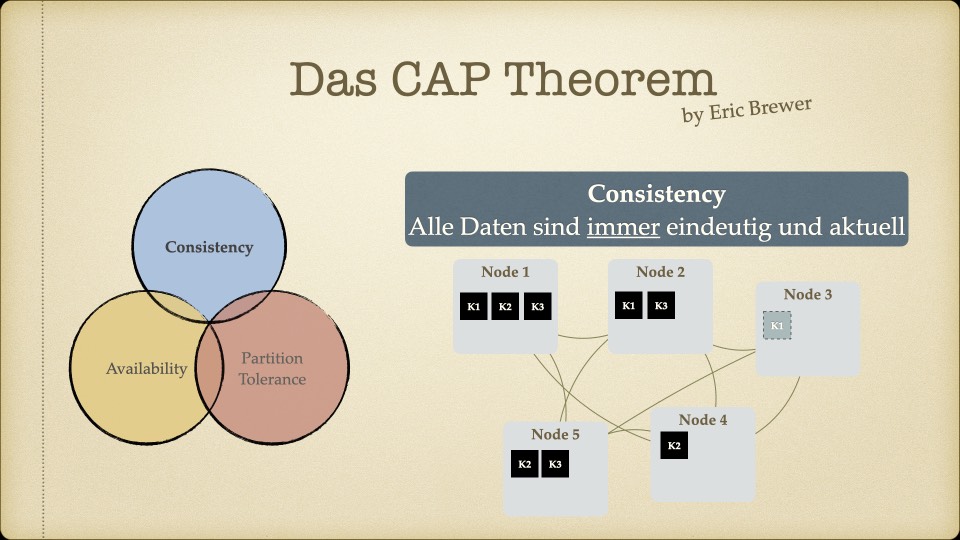
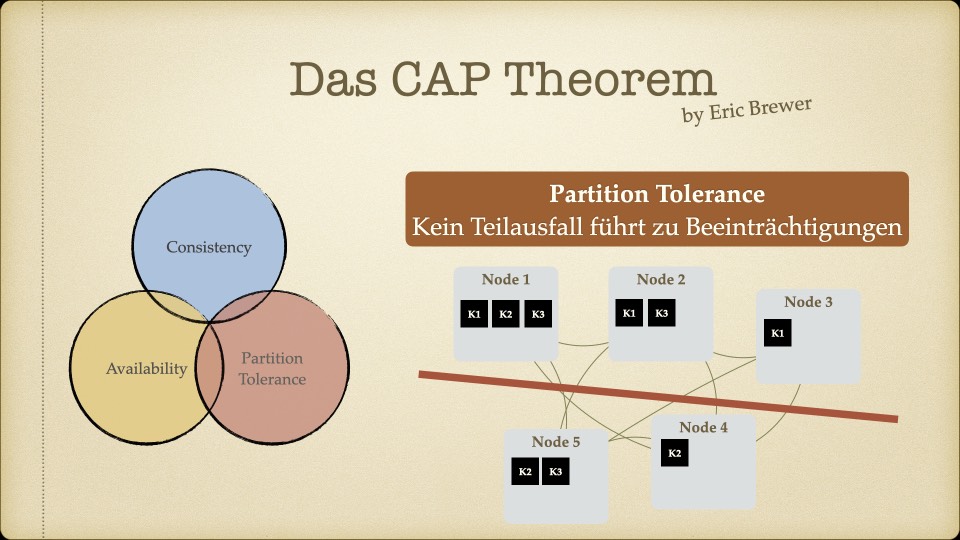
Der Kern des Workshops war das CAP-Theorem – die Erkenntnis, dass verteilte Systeme nicht gleichzeitig konsistent, verfügbar und partitionstolerant sein können. Man muss sich entscheiden, welche zwei Eigenschaften Priorität haben.
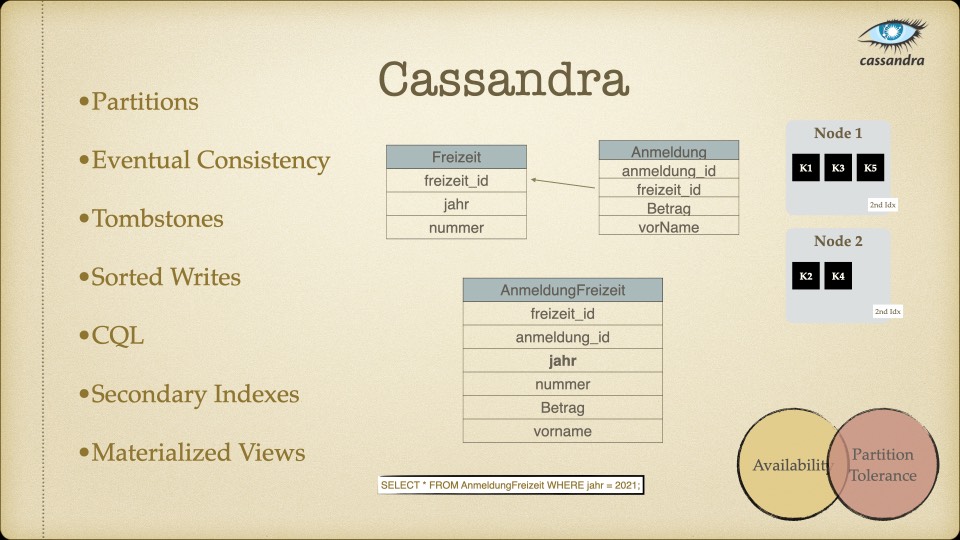
Für unseren Use Case – ein Faktur-System, bei dem Rechnungsdaten unter keinen Umständen inkonsistent sein dürfen – war die Antwort klar: Konsistenz ist nicht verhandelbar. Eventual Consistency, wie sie Cassandra oder MongoDB bieten, kam für uns nicht in Frage. Wenn ein Handelspartner eine Rechnung sieht, muss der Betrag stimmen. Immer.
Warum CockroachDB
Ich habe vier Technologien im Detail vorgestellt – jeweils mit ihrer Position im CAP-Dreieck:
- Cassandra (AP) – Hochverfügbar, aber nur Eventually Consistent. Gut für Logs und Zeitreihen, nicht für Finanzdaten.
- MongoDB (AP) – Flexibles Dokumentenmodell, aber ebenfalls Eventual Consistency. Kein ACID über Dokumentgrenzen hinweg.
- Elasticsearch (AP) – Hervorragend für Volltextsuche, aber keine primäre Datenbank. Bei uns als Datenausschnitt-Schicht vorgesehen.
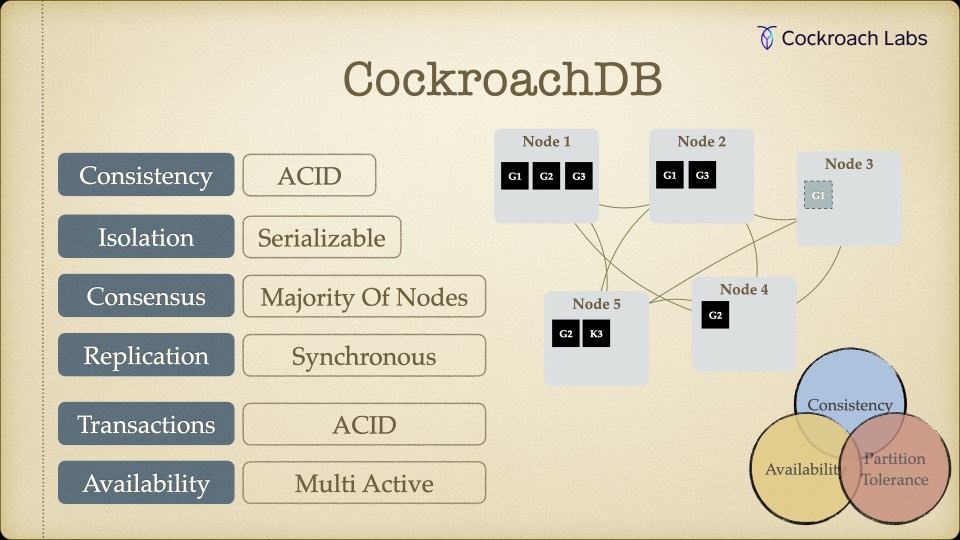
- CockroachDB (CP mit hoher Verfügbarkeit) – ACID-konform, Serializable Isolation, synchrone Replikation. SQL-kompatibel. Und: horizontale Skalierung durch einfaches Hinzufügen von Nodes.
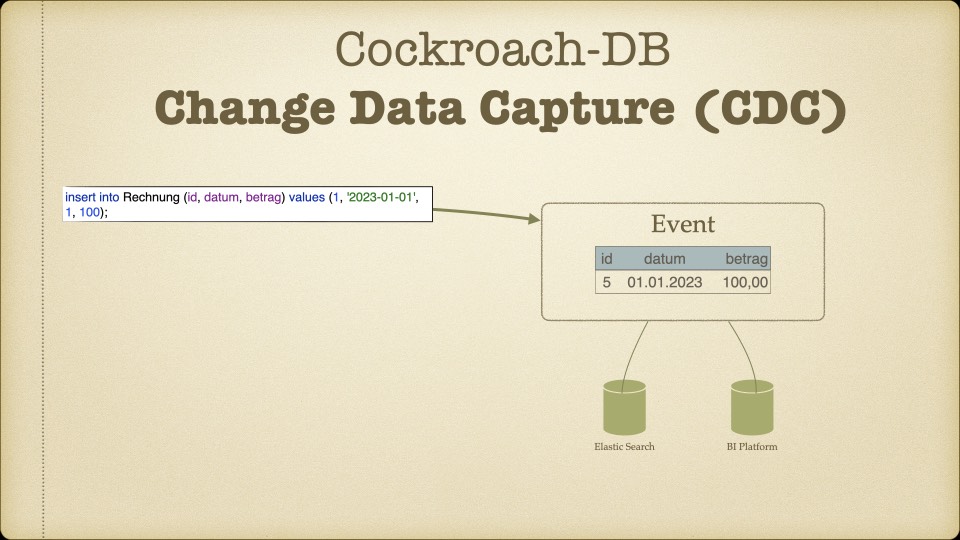
CockroachDB war die einzige Option, die unsere Kernforderungen erfüllte: ACID-Transaktionen auf einer verteilten, horizontal skalierbaren Datenbank. Dazu kamen Features, die direkt auf unsere Architekturziele einzahlten: Change Data Capture für ereignisgesteuerte Verarbeitung und Archival Partitioning für die revisionssichere Datenhaltung.
Die formale Evaluierung: 9 Datenbanken, 4 Ausschlusskriterien
Ein Workshop schafft Verständnis – aber für eine Freigabe durch den Aufsichtsrat braucht man eine nachvollziehbare, dokumentierte Entscheidungsgrundlage. Also haben wir den Auswahlprozess in drei Stufen formalisiert.
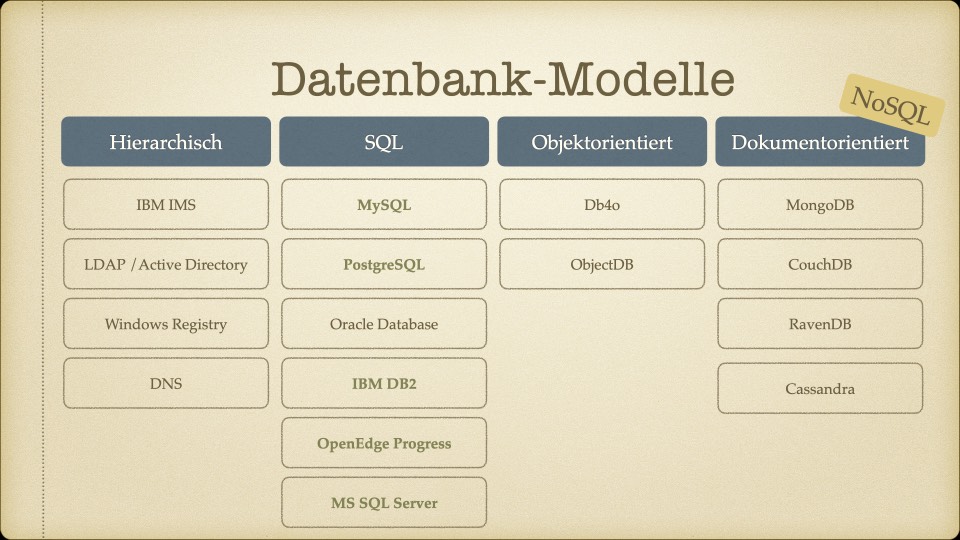
Stufe 1: Welche Datenbank-Typen kommen überhaupt in Frage?
Zuerst haben wir die verfügbaren Datenbank-Typen kategorisiert: hierarchisch, SQL-basiert, objektorientiert und dokumentorientiert (NoSQL). Hierarchische Systeme (IBM IMS, LDAP) und objektorientierte Datenbanken (Db4o, ObjectDB) schieden aufgrund mangelnder Eignung für unsere transaktionalen Use Cases sofort aus.
Stufe 2: Feature-Matrix mit 9 Kandidaten
Für die verbleibenden Kandidaten haben wir eine Feature-Matrix erstellt, die 12 Kriterien systematisch vergleicht:
| Feature | CockroachDB | MySQL | PostgreSQL | Oracle RAC | AWS Aurora | YugaByte DB | Google Spanner | MongoDB | Cassandra |
|---|---|---|---|---|---|---|---|---|---|
| RZ-Betrieb (On-Premise) | ✓ | ✓ | ✓ | ✓ | - | ✓ | - | ✓ | ✓ |
| Replikation | ✓ | - | - | Master/Slave | ✓ | ✓ | ✓ | ✓ | ✓ |
| Horizontal skalierbar | ✓ | - | - | eingeschränkt | limited writes | limited writes | limited writes | limited writes | ✓ |
| Konsistenz | strong, serial | read, limited write | MVCC | read, MVCC | read, limited write | strong, serial | external, true time | eventual | eventual |
| Failover | automatisch | manuell | manuell | manuell | reads only | automatisch | automatisch | reads only | reads only |
| RPO (Recovery Point) | automated, 0 sec | ~1-60 min | ~1-60 min | ~1-5 min | automated, <10s | automated, <10s | manual, <1 min | manual, <1 min | |
| Distributed Transactions | ✓ | - | - | - | - | ✓ | ✓ | multi-document | lightweight only |
| SQL | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | - | - |
| Potential Data Issues | keine | Phantom/Non-repeatable reads, Write Skew | Phantom/Non-repeatable reads, Write Skew | Phantom/Non-repeatable reads, Write Skew | Phantom/Non-repeatable reads, Write Skew | Phantom/Non-repeatable reads | Dirty/Phantom/Non-repeatable reads, Write Skew | Dirty/Phantom/Non-repeatable reads, Write conflicts | |
| System Maintenance | online, rolling | offline | offline | offline | offline | online, rolling | online, rolling | online, rolling | online, rolling |
Stufe 3: Ausschlusskriterien
Aus unseren Architekturzielen haben wir vier harte Ausschlusskriterien abgeleitet. Das Ergebnis war eindeutig:
| Kriterium nicht erfüllt | Ausgeschiedene Systeme |
|---|---|
| Keine Replikation | MySQL, PostgreSQL, Oracle |
| Nicht horizontal skalierbar | AWS Aurora, YugaByte DB |
| Kein SQL | MongoDB, Cassandra |
| Potential Data Issues | alle außer CockroachDB |
Das letzte Kriterium war der entscheidende Filter: CockroachDB war die einzige Datenbank im Vergleich, die bei Serializable Isolation keine bekannten Dateninkonsistenzen aufweist – keine Phantom Reads, keine Non-repeatable Reads, kein Write Skew. Für ein System, das Millionen von Rechnungen verarbeitet, war das nicht verhandelbar.
Google Spanner wäre technisch ebenfalls stark gewesen, schied aber durch die fehlende On-Premise-Option aus – unser Rechenzentrum ist ein nicht verhandelbarer Betriebsort.
Mit dieser dokumentierten Entscheidungsgrundlage – Kategorisierung, Feature-Matrix, Ausschlusskriterien – konnten wir dem Aufsichtsrat nicht nur sagen was wir wollen, sondern nachvollziehbar zeigen warum es genau diese Datenbank sein muss.
Von der Entscheidung in die Produktion
Eine Freigabe ist kein Ergebnis – sie ist ein Startschuss. Zwischen der Aufsichtsrats-Freigabe und dem produktiven Einsatz lagen mehrere Monate intensive Arbeit.
Verhandlung und Partnerschaft mit Cockroach Labs
Der erste Schritt war die Lizenzverhandlung mit Cockroach Labs. Bei einem 6-stelligen Investment und einer strategischen Plattformentscheidung geht es nicht nur um den Preis pro Node – es geht um Support-Level, Update-Garantien und die Frage, wie eng der Hersteller bei der Einführung begleitet. Wir haben uns für ein Paket entschieden, das neben den Lizenzen auch professionelle Begleitung durch Cockroach-Consultants umfasste.
Pilotcluster und begleitete Workshops
Bevor wir produktive Daten anfassten, haben wir einen Pilotcluster aufgesetzt – eine isolierte Umgebung, in der wir Architekturentscheidungen validieren konnten, ohne Risiko für den laufenden Betrieb. Die Consultants von Cockroach Labs haben uns in mehreren Workshops durch die optimale Cluster-Konfiguration geführt: Node-Sizing, Replikationsfaktoren, Netzwerk-Topologie, Backup-Strategien. Wissen, das man sich nicht aus der Dokumentation anliest, sondern das aus der Erfahrung mit hunderten Produktiv-Installationen kommt.
Das war eine bewusste Entscheidung: Wir hätten den Cluster auch alleine aufsetzen können. Aber bei einer Infrastrukturkomponente, die zum Fundament der gesamten Plattform werden soll, ist “funktioniert irgendwie” nicht gut genug. Es muss von Anfang an richtig stehen.
Heute: Produktiv und wachsend
Inzwischen ist CockroachDB produktiv im Einsatz und wird von immer mehr Teilprojekten als zentrale Datenbank genutzt. Unsere laufenden Migrationsprojekte – die schrittweise Ablösung der Legacy-Systeme – machen die verteilte Datenbank Stück für Stück zum tragenden Element der neuen Architektur.
Der Weg dahin war nicht ganz ohne Reibung. In einem Konzernumfeld mit begrenzten Ressourcen kann ein genehmigtes Investitionsbudget auch unerwartete Herausforderungen verursachen. Es gab eine Phase, in der interne Budgetkonkurrenz zu Spannungen führte – inklusive Diskussionen darüber, ob die Entscheidungsgrundlagen transparent genug kommuniziert worden waren. Im Rückblick hat sich gezeigt: Unsere Dokumentation war lückenlos, der Entscheidungsprozess nachvollziehbar. Solche Situationen gehören zu strategischen Investitionen dazu – sie bestärken aber umso mehr die Überzeugung, dass ein sauberer, gut dokumentierter Entscheidungsprozess nicht optional ist, sondern Schutz bietet.
Wie weit das Projekt gekommen ist, zeigt ein Blick auf das Budget: Für 2025 gibt es zwar noch eine eigene Budgetposition für die verteilte Datenbank – aber wir werden sie voraussichtlich nicht benötigen. Der produktive Cluster läuft, neue Projekte starten direkt auf CockroachDB, und bestehende Systeme werden im Rahmen unserer Migrationsprojekte sukzessive überführt. Was vor zwei Jahren ein strategisches Investment mit eigener Budgetlinie war, wird absehbar zu einer regulären Betriebsposition – so selbstverständlich wie Strom und Netzwerk.
Fazit
Der Weg von der ersten Problemanalyse bis zur produktiven Datenbank war kein Sprint – er war ein Marathon über mehrere Etappen: Problemanalyse, Architekturvision, Lenkungskreis-Präsentation, Bereichsleiter-Workshop, formale Evaluierung, Aufsichtsrats-Freigabe, Herstellerverhandlung, Pilotbetrieb, Produktion.
Was ich daraus gelernt habe:
- Technologieentscheidungen dieser Größenordnung sind Geschäftsentscheidungen. Sie müssen technisch fundiert sein, aber in der Sprache des Business argumentiert werden. Nicht “verteilte Datenbank mit Serializable Isolation”, sondern “keine Ausfälle, keine Dateninkonsistenzen, Skalierung ohne Limit”.
- Ein strukturierter Entscheidungsprozess überzeugt mehr als Begeisterung. Die Feature-Matrix mit klaren Ausschlusskriterien hat dem Aufsichtsrat gezeigt, dass wir nicht aus dem Bauch heraus entschieden haben, sondern methodisch. Das schafft Vertrauen.
- Investiere in den Anfang. Die Workshops mit den Cockroach-Consultants haben sich vielfach bezahlt gemacht. Fehler in der Cluster-Konfiguration hätte man Monate später teuer korrigieren müssen.
- Das beste Zeichen für Erfolg ist Unsichtbarkeit. Wenn eine Technologie nicht mehr als Projekt geführt wird, sondern als Betrieb – dann ist sie angekommen.